puppeteerでファイルをダウンロードを実装する
tl;dr
- ブラウザの自動操作はpuppeteerがおすすめ
- ファイルのダウンロードもできる
- サーバレス環境で動かそう
Why
例えば、領収書や請求書などの書類の月次ダウンロードを定型業務がある会社は多いはず。
その定型業務を自動化するソリューションとしてユースケースを単純化したサンプルを紹介する
実現方法の一例、ブラウザ操作の自動化で使われるメジャーなツールとしてpuppeteerを利用する
目次
- puppeteerを動かすアプリケーションを作成する
- puppeteerをローカルにてDockerで動かす
- puppeteerで対象ページにあるファイルをダウンロードする
- 上記をGitHub Actions環境で実行する
- ダウンロードしたファイルをArtifactへアップロードする
上記のフローで実現できるとよい
4からはおまけみたいなもので、本来はCloudRunなどサーバレスなパブリッククラウド環境でよいので、定期実行するとよい。
個人的にはCloudRun+GCSにダウンロードをしたものを保存することをおすすめしている。
今回はサンプルというのもあり、GitHub(+GitHub Actions)の機能で完結できる環境にした
サンプルソースコードは以下にあるので参考にしてほしい。
1. puppeteerを動かすアプリケーションを作成する
スクレイピングサイトの準備
github-page機能でのホスティングにてPDFをaタグをdownload属性をつけてgithub-pageにホストしたページを作成している
このサイトを請求書等が置かれている想定でブラウザで自動ダウンロードさせる想定

アプリケーション構成
expressでさくっとWebサーバをたてて、リクエストハンドラを作り、httpリクエストを受けてスクレイピングを実行する構成とする
httpリクエストエンドポイントがあることでサーバレス環境、例えばCloudRunやCloudFunctionsで実行可能となるため。
OnOffのジョブ形式やコマンドラインで実行したい場合はコマンドラインツール的なものを用意するでもいいと思う。
コードを抜粋
app.use(async (req, res) => {
console.info("[main] version:" + process.env.npm_package_version)
const result = await getPDF()
console.info(`[main] result:${result}`)
})getPDF関数にpuppeteerによるPDF自動ダウンロードを記載している
// Download PDF
async function getPDF() {
let result = false;
const browser = await puppeteer.launch({ args: ['--no-sandbox']});
try {
const page = await browser.newPage();
await page._client.send('Page.setDownloadBehavior', {
behavior : 'allow',
downloadPath: resolve(__dirname,'.','downloads')
});
console.info("[getPDF] download path", resolve(__dirname,'.','downloads'))
// ダウンロードページへ遷移
await page.goto(targetURL)
console.info("[getPDF] goto targetURL")
await page.waitForSelector('#pdf1')
console.info("[getPDF] finished download page")
await page.click('#pdf1');
console.info("[getPDF] download click")
// 念の為10秒待つ
await page.waitForTimeout(10000)
console.info("[getPDF] download finished")
result = true;
// For debug
const html = await page.content();
console.log(html);
// For debug
const filePath = '/tmp/screenshot.png'
await page.screenshot({ path: filePath, fullPage: true });
} catch (e) {
console.error(`[getPDF] err: ${e}`)
result = false;
}
finally {
console.log(`[getPDF] close`)
await browser.close();
return result
}
}いくつかポイントを列挙する
- ダウンロード先のディレクトリを指定する
setDownloadBehaviorメソッドで、 ファイルのダウンロード指定を行う
任意のパスで良いと思うが、カレントディレクトリのdownloadsを指定した
const browser = await puppeteer.launch({ args: ['--no-sandbox']});
const page = await browser.newPage();
await page._client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: resolve(__dirname, '.', 'downloads')
})あとはpuppeteerの基本的なメソッドをつかってページ遷移してダウンロードを押下している内容となる
ポイントとしては、
- 必要以上にconsole.infoで標準出力にログを垂れ流す
スクレイピングはHTML構造が変更されることが多く、
運用はじまって時間が立つほど期待した結果が得られる可能性は下がりがちになる
console.info使ってステップバイステップで標準出力ログは必要以上に残しておくとよい
- キャプチャを取る関数を用意しておく
エラーが起きた時点で スクリーンショットをとれるように準備しておくとよい
const filePath = '/tmp/screenshot.png'
await page.screenshot({ path: filePath, fullPage: true });
テスト実行でpuppeteerを動作させる
Jest経由で実行すると、OneOffのジョブとして実行することも可能である
app.test.jsを用意して、expressのハンドラから実行される関数だけを呼び出すようにした
テスト実行にてJest経由でリクエストハンドラで呼ばれる関数をキックすることで実現しているので 参考にしてほしい
import request from 'supertest'
import {app} from './app.js'
describe(`Get PDF`, () => {
test(`GET`, (done) => {
request(app)
.get(`/`)
.then((res) => {
expect(res.statusCode).toBe(200)
expect(res.text).toBe(`OK`)
done()
})
.catch((err) => {
done(err)
})
})
})
2. puppeteerをローカルにてDockerで動かす
Dockerfile
Dockerファイルの作成のポイントを記載する
- ベースは以下の公式のドキュメントを参考にする
https://github.com/puppeteer/puppeteer/blob/main/docs/troubleshooting.md
- node:slimを選ぶとよい
サイズを減らす努力をしてnodeのalpineベースを選んでもよいのだが、
ダウンロードしたファイルの日本語のフォント問題やらライブラリ不足が指摘されやすいため
FROM node:16.13-slim
RUN apt-get update \
&& apt-get install -y wget gnupg \
&& wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - \
&& sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' \
&& apt-get update \
&& apt-get install -y google-chrome-stable fonts-ipafont-gothic fonts-wqy-zenhei fonts-thai-tlwg fonts-kacst fonts-freefont-ttf libxss1 gconf-service libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget \
&& rm -rf /var/lib/apt/lists/*
# Add pptr user.
RUN groupadd -r pptruser && useradd -r -g pptruser -G audio,video pptruser \
&& mkdir -p /home/pptruser/Downloads \
&& chown -R pptruser:pptruser /home/pptruser \
&& mkdir -p /app \
&& chown -R pptruser:pptruser /app
# Run user as non privileged.
USER pptruser
WORKDIR /app
COPY --chown=pptruser:pptruser package*.json ./
RUN yarn install
COPY --chown=pptruser:pptruser ../../.. .
CMD ["yarn", "start"]
docker-compose
version: '3.8'
services:
app:
build: ..
command: yarn start
ports:
- 8080:8080
volumes:
- .:/app
- trick:/app/node_modules
environment:
- PORT=8080
volumes:
trick:
ポイントしては
- ファイルダウンロード先をDockerfileのVolume指定する
ファイルダウンロード先をDockerfileのVolume指定することで
ホストからでもファイルを参照できるようにするとよい
- サーバレス環境でデプロイした実行した場合には保存されないので クラウドストレージに保存する必要がある
以下のイメージでGCSにストリームして書き込むとよい
import Storage from '@google-cloud/storage'
let gcs
const files = fs.readdirSync(resolve(__dirname,'.','downloads'))
const pdfFiles = files.filter(f => f.includes('.pdf'))
const bucketName = "xxxx"
const results = []
pdfFiles.forEach(fileName => {
const targetFullpath = resolve(__dirname, '.', 'downloads' + '/' + fileName)
writeToGcs(targetFullpath, bucketName, fileName)
})
async function writeToGcs(readFile, bucketName, writeFile) {
gcs = gcs || new Storage()
const bucket = gcs.bucket(bucketName)
console.log(`bucket: ${bucketName}, file: ${writeFile}`)
const file = bucket.file(writeFile)
const src = fs.createReadStream(readFile)
const stream = file.createWriteStream()
src.pipe(stream);
return true
}3. puppeteerで対象ページにあるファイルをダウンロードする
さて、実装もDocker環境もととのったところで 、ローカルからDocker環境経由で実行する
docker compose upにて立ち上げて、curl http://localhost:8000する
するとpuppeteerが起動して、自動ダウンロードして、downloadsフォルダにpdfが取得できる
4 GitHub Actionsからpuppeteer実行して、ダウンロードファイルを取得する
ここからはおまけな話で、
jobs:
lint:
name: Test
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Get yarn cache
id: yarn-cache
run: echo "::set-output name=dir::$(yarn cache dir)"
- name: Setup Node 16.x
uses: actions/setup-node@v1
with:
node-version: 16.x
- name: Install
run: yarn install --frozen-lockfile
- name: Test
run: yarn test
- name: List files in the repository
run: |
ls ${{ github.workspace }}
- name: Archive production artifacts
uses: actions/upload-artifact@v2
with:
name: Download Files
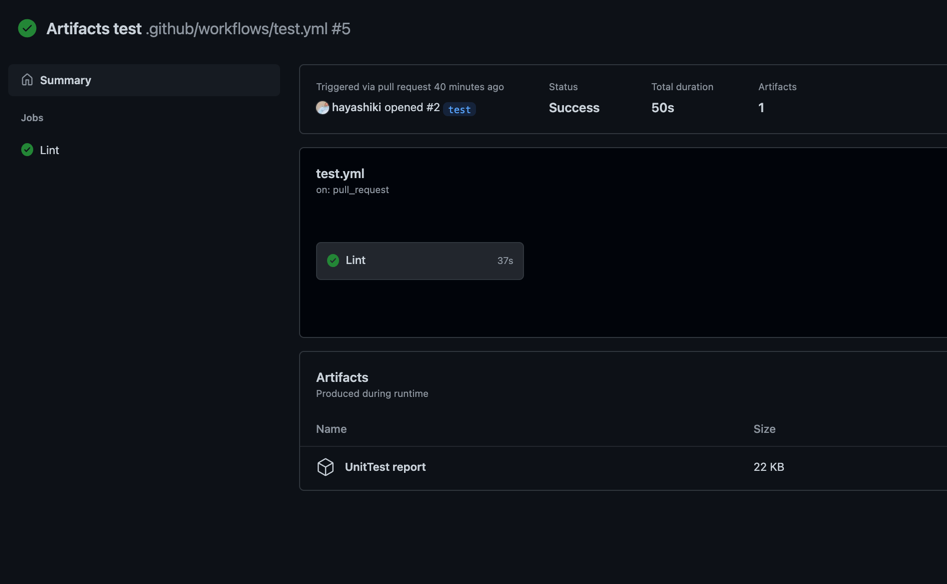
path: downloadsArtifactsにアップロードされていることが確認できる
補足
副次的な話になるが、 ミニマムなpuppeteer検証環境があることで、予期せぬ挙動があったときに
それがHeadlessChrome、Node、puppeteerのバージョンのどれが原因か切り分けやすくなった